国内还是有很多公司做的,opencode在做个差不多的壳子起步还是比较快的, Reasonix是deepseek的,Qoder是阿里的。大部分也都是先cli再gui的路子。
说起来ai还是牛逼啊,逼得苹果做容器工具了。搞的微软现在windows要倒回去抱住wsl的腿
3 个赞
deepseek的agent工具名字都有了?
刚刚查了下,原来是基于DeepSeek的开源项目
为deepseek专门优化的开源agent平台,比直接用opencode或者跨用codex,Claude code要好用很多,不是deepseek官方的。
qoder原来也更新这种桌面端了吗,感觉这种产品应该往消费端上靠而不是在定位在开发工具上。openai也要把codex和chatgpt合并了
Kimi K2.7 Code 编程模型已上线 Kimi Code、API 开放平台
内外部基准评估显示,Kimi K2.7 Code 相比 K2.6 模型显著提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均 token 消耗减少 30%。
我们还将提供 Kimi K2.7 Code 高速版,同一个模型,但输出速度约为普通版的 5-6 倍,常规编程场景下(取输入长度中位数)输出速度约 180 Token/s,短上下文场景可达 260 Token/s ,带来更极致的编程体验。
下周一,6月15日,企业和开发者可通过 Kimi API 开放平台调用高速版模型,6x 速度仅需 2x 价格。
信息源:https://mp.weixin.qq.com/s/NBw1VAA9MjpKv-Rirq9qDg

另外Kimi正计划推出AI原生信用卡,现已开启预约(预约不等于申办信用卡)。
信息源:Kimi官方小红书
2 个赞
这都能“AI原生”吗,何意味
kimi缺钱,一直说是考虑上市也没上,弄个信用卡也是多搞点米
1 个赞
Kimi好歹是清华系的,DeepSeek出来后差一点死了靠融资活过来了,总体上而言相对缺钱缺算力
已经快12点了,有无哨骑探报
是论文复读,没新东西 ![]()
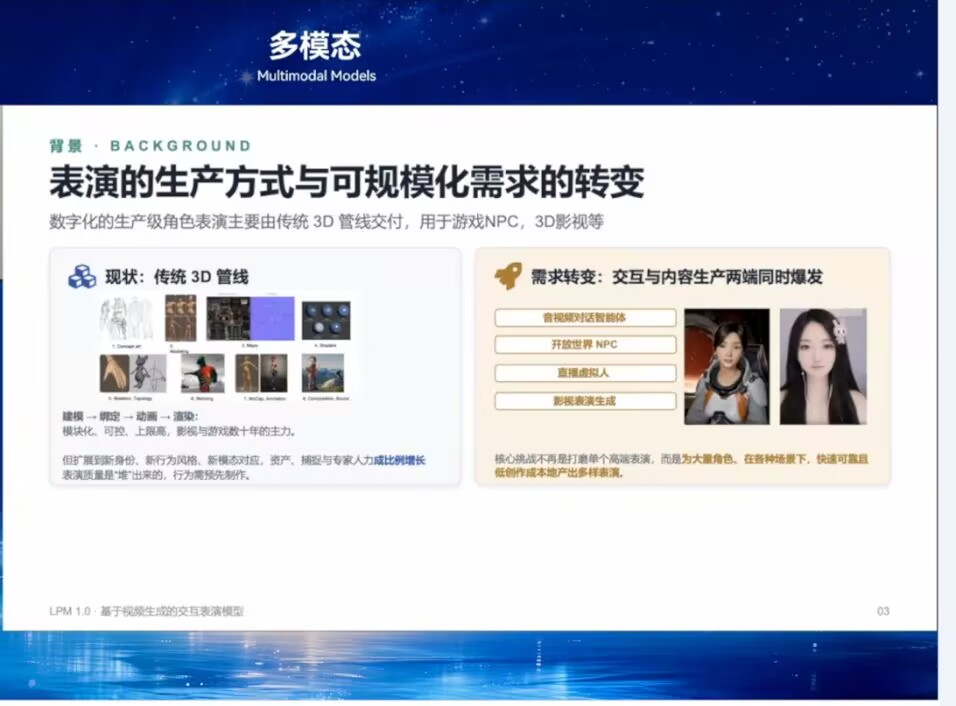
但是她提到了一个LPM数据集的问题。因为对话是两个人的事,公开视频资源里面,比如访谈,大多数镜头都是对着正在说话的那个人,倾听者的表情是很稀缺的(她说只占10%),所以怎么解决倾听者数据是一个难点。
这里我想起了米之前在上海招募过一批线下对话者,也是一对一的,我估计就是为了解决数据集问题。

4 个赞
曾老师无论是演讲还是回答问题都很游刃有余,由内而外散发着自信,Anuttacon确实是大佬云集,听完对米搞AI更有信心了。
2 个赞
这个最逆天的是在美国境内的非美国国籍人员也禁止了,还包括了A社的外籍员工,可行性可以直接说就是零,美国连非法移民都搞不定还想搞进一步人群细分,所以结果只会是直接把模型下了不让用,其实核心还是A社只会把模型往大去堆,但成本现在很明显控不住了,只能各种找借口限制人们去用,同时还得营销自己的能力依旧断层领先。
8 个赞
原来还有这事,如你所愿了 ![]()
5 个赞
刚看知乎,华子重启盘古了?这是准备进来分杯羹?
1 个赞
但我记得华为这个部门一直都是坨大的
2 个赞
华为的大模型是国内前五都进不了的水平,比混元还次,当时关停什么套壳千问都是表象关键还是自己能力太拉了
4 个赞
余承东的宣发真的是味大啊,华为在全世界都不知道大模型是何物时发布了盘古,华为要做就做世界领先,就这宣发一听就不是准备和技术向的人说的,估计是盯上G的大项目了
4 个赞